

セキュリティの運用現場で生成AIを活用することのリスク
はじめに
前回の記事「セキュリティ人材不足に待ったをかける!生成AIを活用したセキュリティ運用 」ではセキュリティアラート運用において、生成AIを活用した業務効率化を提案しました。生成AIは機械的な作業を人間より遥かに速く・正確に処理することができ、運用現場に革命を起こしていると言えます。しかし、光射すところには影があり、それは生成AIも例外ではありません。
今回はセキュリティの運用現場で生成AIを活用することのリスクについて考えます。
(おさらい)セキュリティ運用で生成AIを活用する
まず本題に入る前に、前回の記事の内容を復習しましょう。
前回の記事では、人手不足が深刻化しているセキュリティ現場の対策となるアプローチとして、セキュリティのインシデントを生成AIに解釈させ、一次情報の質を向上させようという提案をしました。AWSの生成AIマネージドサービスである Amazon Bedrock*を利用し、インシデントが発生したらリアルタイムで Bedrock に解釈を行わせるデモを紹介しています。
*Amazon Bedrockとは、トレーニング済みのAI基盤モデルを簡単に利用できるAWSフルマネージドサービスです。
(参照: https://aws.amazon.com/jp/bedrock/)
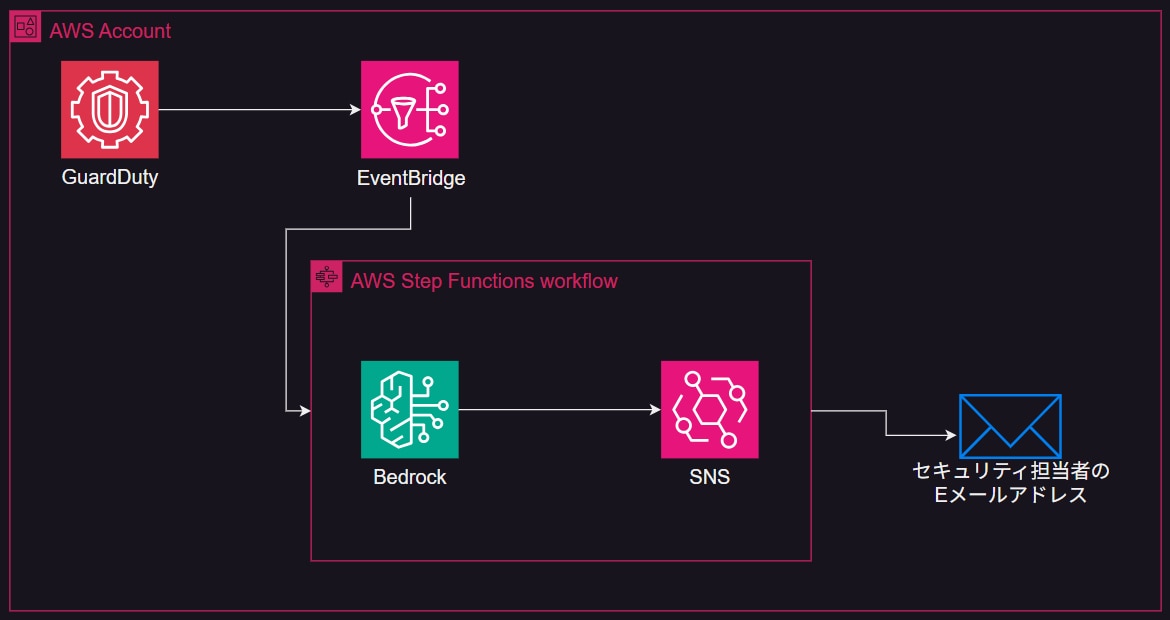
この提案は一見すると、セキュリティ担当者の運用負荷を劇的に改善する完全無欠な方法に思えます。たしかにインシデント対応において、検知ツールから受け取る一次情報が人間にとって読みやすい形に解釈されることは、運用負荷の削減に大きく貢献します。
毎日多くのインシデントに対応する現場のエンジニアにとっては、一日でも早く導入してほしいと願うソリューションです。仮にインシデントが増加してトラフィックが逼迫した場合のシステムダウンを懸念する方がいるかもしれませんが、上記のアーキテクチャはすべてサーバレスなコンポーネントで構成されており、各サービスのクオータ制限に引っかからない限りは安定してサービスを提供できます。
ですが、この構成にも実はリスクとなる穴が存在します。以降では、セキュリティの運用現場で生成AIを活用することのリスクについて、いくつか例を挙げて考察します。
ハルシネーション
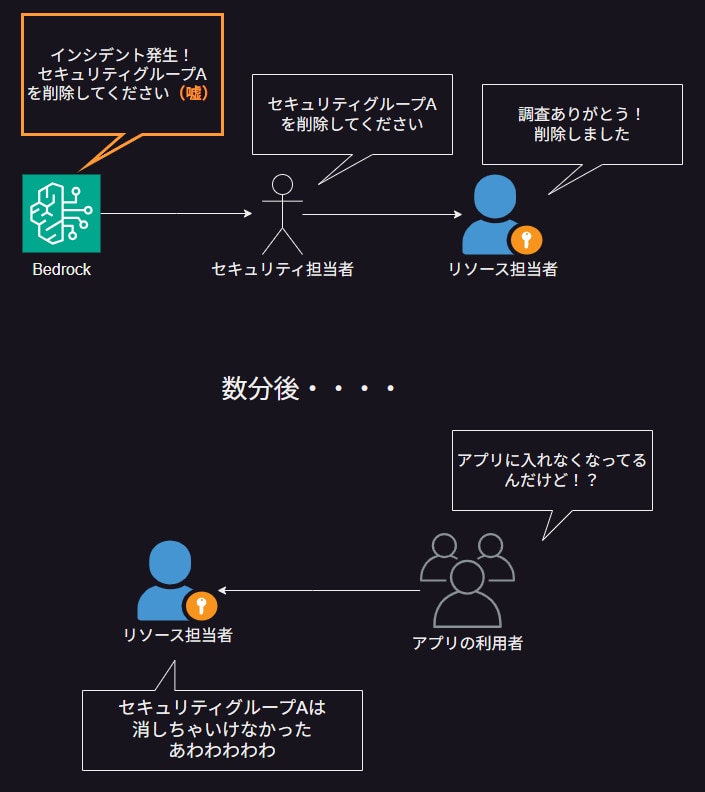
「ハルシネーション(Hallucination)」という言葉をご存知でしょうか。これは直訳すると「幻覚」という意味の英単語で、生成AIの用語だと「生成AIがもっともらしい嘘をつく」という意味です。前回の記事での提案では、生成AIによって解釈されたメッセージをそのままリソースの担当者に連携し、インシデント対応を図るという運用を想定しています。しかし、この運用には落とし穴があります。それは、生成AIが本当に正しいことを言っているかを気にしないまま、インシデント対応フローを進めてしまっていることです。
生成AIは、自分の持っている知識を正しいと信じて素直に回答する健気な子です。生成AIの基盤モデルがセキュリティインシデントの対応方法に明るくない場合、もしくは生成AIに読み込ませたデータソースに誤りがある場合、生成AIはそれでも何の疑いもなく回答を生成します。もし、「もっともらしい嘘」を正しい回答としてリソースの変更を行ってしまったらどうなるでしょうか。生成AIによって、意図しない二次被害が発生してしまいます。
以下の図では、生成AIがハルシネーションを起こしたことにセキュリティ担当者が気づかず、そのままリソース変更を行ってしまい、アプリケーションに被害が出てしまう例を示しています。
ではこのようなハルシネーションを防ぐにはどうしたらよいのでしょうか。
まずは、生成AIの回答は必ずしも正しいとは限らないことを理解しましょう。生成AIはそれっぽい回答を高速に生成してくれるので、ついつい信じてしまいがちです。生成AIから受け取る回答はあくまで参考情報であり、重要な情報は自分で確認する癖をつけましょう。本番環境のリソース情報ならなおさらです。
また、生成AIにインプットさせるデータソースの正確性には細心の注意を払いましょう。生成AIにインシデント対応方法のドキュメントを読ませてそれに基づいた回答をさせる、いわゆるRAG(検索拡張生成)* を用いる場合、データソースに誤りがあったら元も子もありません。データソースは会社もしくは業界のコンプライアンス規定を満たしているものを使用することを原則とし、誤った回答を生成させないような工夫が必要です。
*参照:RAG (検索拡張生成) とは何ですか?https://aws.amazon.com/jp/what-is/retrieval-augmented-generation/
過検知
次は別の角度から生成AIを活用するリスクを考察します。
AWSでは最近のアップデートにより、Amazon Qに自然言語でリソースの情報を質問すると、その設定情報を返してくれるようになりました。Amazon QとはAWSの生成AIサービスのひとつであり、簡単に言うと「マネジメントコンソールに常駐するあなた専用のチャットボット」です。AWS的には、AWSの操作で困ったことがあったらまずAmazon Qに聞いてね!というスタンスで、最近リソースの情報まで検索できるようになアップデートがあって盛り上がっていました。セキュリティ担当者がインシデントの調査をするときに、リソースの情報をキャッチアップするのは労力がかかるポイントであり、これを活用すると原因の早期特定に役立ちます。
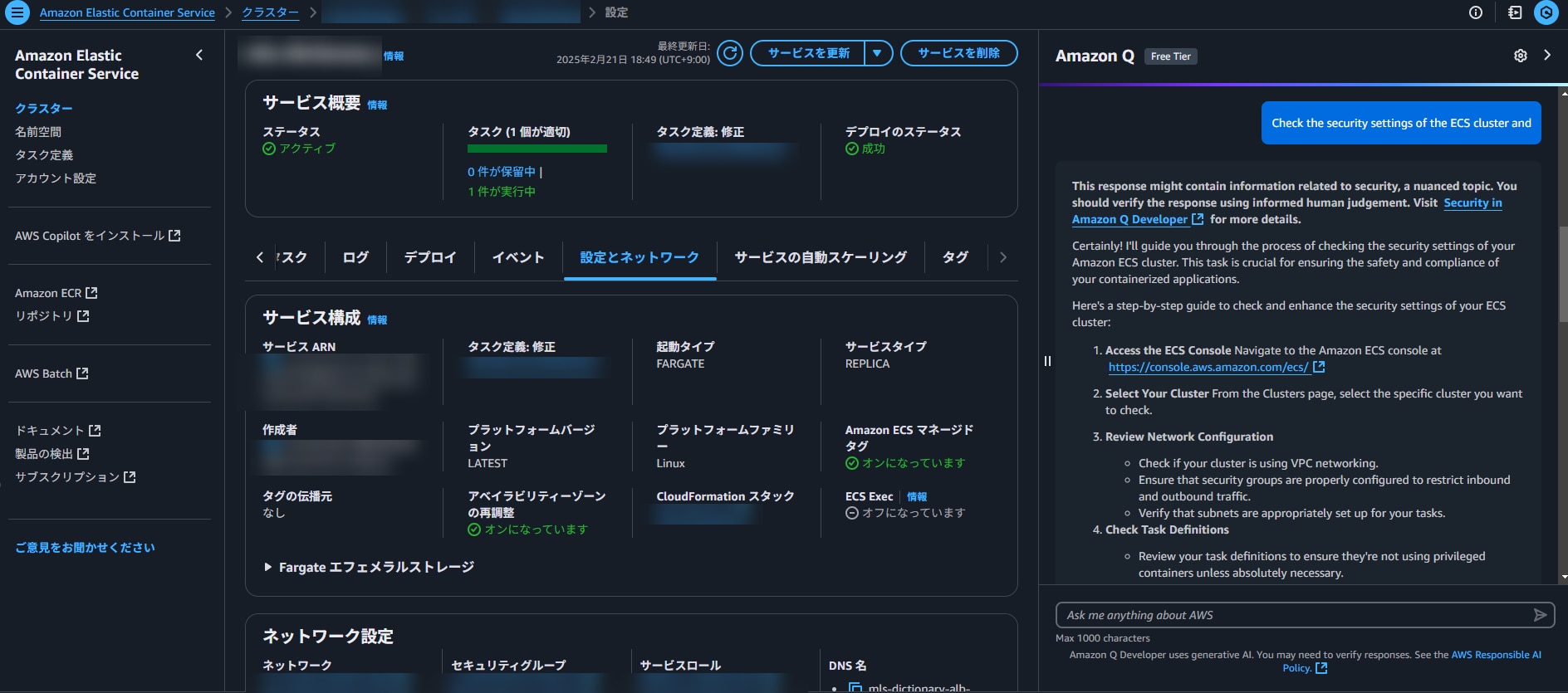
簡単にリソースの情報が便利ですね。
ところでGuardDutyを見てみると、以下のようなインシデントを検知しています(!?)。
High:「anomalously invoking APIs commonly used in Persistence tactics.」
なんだか危なさそうなインシデントです。Amazon Qにリソースの情報を聞いただけなのにセキュリティインシデントが発生してしまうのはどういうことでしょうか。これを放置しているとセキュリティ担当者に通知が飛び、彼らの仕事が増えてしまいます。
これは何が起きているかというと、Amazon Qがユーザに代わってAPIを呼び出していることが原因です。GuardDutyはAWSアカウント内の、普段と違う行動を見つけて検知するサービスです。上記のAmazon Qのリソース情報取得の仕組みは、Amazon Qがユーザの権限を利用して、リソースの情報を取得するAPIを呼び出し、それを画面に出力しているという流れです。GuardDutyからしてみれば、普段はユーザが自分でリソースを取得しているのに、今回は違う人がユーザの権限でリソースを見ているぞと考えて、このアクションを過検知しているのです。
Amazon Qに限らず、AWSアカウント内をスキャンするソリューションはいくらでもありますが、これらをGuardDutyのようなセキュリティソリューションが過検知してしまう現象にはどのように対処したらよいのでしょうか。これに対して完璧な対応策はないと考えていますが、セキュリティ担当者はこれらの過検知を拒否する/許容することのルール作りをすることが重要です。すべてのインシデントに対して真面目に対応していたらアラート疲れに陥ってしまいますし、かといって上記タイトルのインシデントをすべて無視したら、本当の攻撃に気が付けなくなって本末転倒です
どちらを重要視するかは組織次第としか言えませんが、生成AIの行動における過検知の扱いについては、社内ポリシーを定めておくと運用がスムーズになると考えています。
まとめ
この記事では、 セキュリティの運用現場で生成を活用することのリスクについて考えました。生成AIはまだまだ発展途上の技術であり、上記のような問題はいずれ解消するかもしれません。ただ、技術の進歩に影はつきもので、今後も同じようなジレンマは繰り返すでしょう。
本記事が、生成AIを活用する際のリテラシーを見つめなおすきっかけになれば幸いです。
弊社では、セキュリティポリシーの策定・改定支援や、セキュリティ教育プログラムにより、企業全体のセキュリティリテラシーの底上げを図っております。 他にも、パブリッククラウド環境のセキュリティ対策として純国産CNAPPやそのSOCでの運用サポートも 提供しています。


